
Although sceptical at first, I have to admit the Amazon Kindle is one of my better gadget purchases. I used to prefer to buy books to decorate my shelves - used books at that, as a well thumbed paperback has more character than one which appears new and unread. I wasn't convinced that an eReader was a good idea but with all my travelling on trains and planes in 2011 and the Kindle 4 down to an almost throwaway £89 I decided to take the plunge and have a go.
The Kindle is great. There's the convenience of popping online over WiFi and buying a book which is instantly available to read, the crisp, clear e-ink display, the convenient light provided by the official Amazon case (at extra cost but worth it), the capacity to hold hundreds of titles, the synchronisation of the Kindle service between my eReader, Android phone and iPad and the anonimity of being able to read something in a public place without feeling that I'm being judged by the snooty student ponce sitting next to me because he's pretending to read Kafka or Dostoyevsky while I'm reading The Very Hungry Caterpillar (again).
Recently Nigel and I each enrolled onto a retraining course and several A4 binders of course notes were duly dumped onto our respective doormats by disgruntled hairy-arsed couriers. Rather than cart around all this dead-tree material, we figured it would be better if we scanned them as PDF's and copied them onto our Kindles for easy viewing at our leisure.
Simple, yes?
Well.... no.
Although it's true that a Kindle will display a PDF, we found the experience to be very poor with our virgin scanned docs. There was too much wasted space around the core text, headers and footers were getting in the way and the font rendering was choppy at best. We spent some time trying different methods and conversion tools on Windows, Linux and Mac and in the end the only sure-fire way to get a good result using free software was on Windows. Which is unfortunate as we're both primarily Linux users.
Never mind. Here is our six step process for getting a scanned document to show neatly and clearly on a Kindle...
Step 1. Scanning
My particular document has 22 pages and the original is on A4 paper that has been printed double-sided. Fortunately I have at my disposal a scanner with automatic document feeder and duplex scan capability. I'm scanning in greyscale because the document has diagrams and the Kindle 4 doesn't have a colour screen. Scan resolution is 300dpi and the output file type is PDF. With these settings my 22 page document is 6.37MB in size and is practically unreadable if plopped directly onto the Kindle. Some magical, fantastical manipulation is therefore required.
Step 2. Crop
I'm using Briss, a free cross-platform tool that can crop a PDF document. When the document is opened in Briss it will overlay all the odd pages and all the even pages allowing you to set selection areas that exclude wasted space, headers and footers. Once selected, click Action / Crop PDF and the new file will be saved as [filename]-cropped.pdf
 Briss showing an overlay of odd pages (left) and even pages (right). The selected areas cut out headers, footers and whitespace.
Briss showing an overlay of odd pages (left) and even pages (right). The selected areas cut out headers, footers and whitespace.
Step 3. Rescan
Using the tool pdfr (Windows only, sadly), the cropped PDF file is rescanned using the default options and the resulting output is both much sharper and reduced in file size. The output file will have a -r.pdf suffix added to the filename to distinguish it from the original file. After using pdfr, my file is reduced to 1.43MB in size and if copied to the Kindle is much more readable but there is still room for improvement.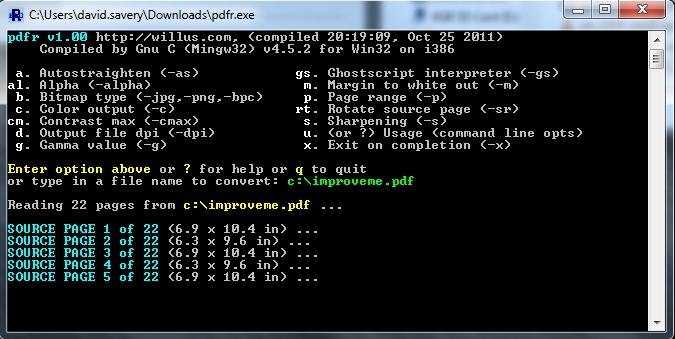
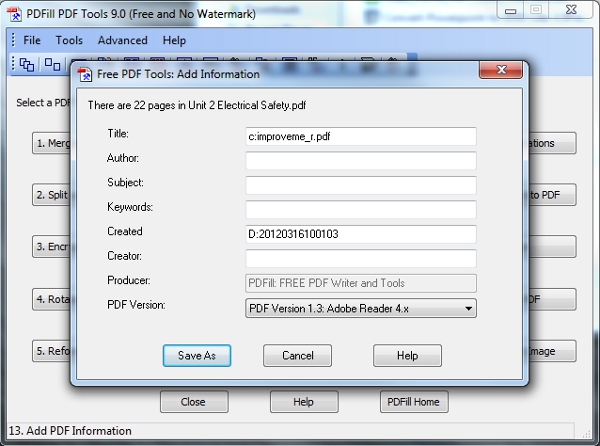
Step 4. Rename
One problem with the pdfr output is that the book title is altered in the properties of the PDF itself. Even if you change the PDF filename, the Kindle will display the title which may be something completely different and will have both a -r.pdf suffix and a drive letter prefix after its been run through the rinse cycle on pdfr. For example, a PDF file that had the filename My Book.pdf before conversion will appear more scrappily as c:My Book-r.pdf when viewed on the Kindle. It's not possible to edit the title using Acrobat Reader but there are free utilities that will do it and I'm using another Windows app called PDFill PDF Tools. Once the title has been altered using this tool, the file can be re-saved.
Step 5. Conversion
Although by this point the quality of the file has been much improved, converting it to a MOBI file will make it much better. For this I'm using Calibre, a cross-platform eBook management app. The PDF is dropped into the Calibre library and the Convert Books option is used to make it into a MOBI file using the default options. The output file in this case increases to 4.22MB but is still smaller than the original scan. The output file is located under My Documents/Calibre when used with Windows.
Step 6. Send to device.
The MOBI file is now ready to be sent to the Kindle. This can be done either with Calibre by hooking up the Kindle to the computer's USB port or by sending to your documents email address set up with Amazon. At this point the file, when viewed on the Kindle, should be much much clearer and more readable than when it was in any of its previous PDF forms. You can magnify it further by pushing the down button on the Kindle D-pad which will select the text on the page and allow you to zoom in.
The full monty.
So the Kindle can read PDF's - but not necessarily terribly well out of the box. You may also wonder why we don't just cut out steps 3 & 4 and use Calibre to convert the original PDF to a MOBI file. Well, we tried that. We tried lots of things including Amazon's conversion service but so far the only method we've found that provides the quality we expect is to follow all the steps. Indeed, using Calibre to convert the original PDF also caused the output MOBI file to be orientated in landscape mode which is pretty ridiculous as *nobody* wants the arsehole of switching between portrait and landscape on a device that has no accelerometer*.
We're open to any simplified ways of getting a scan onto a Kindle quickly and cleanly if anyone out there has any ideas!
* 100% fact.